
Während hingegen aktuellere Tendenzen wie Clean Code Developer in der Softwareentwicklung den Entwickler selbst als Mensch in den Fokus rücken und ihm ein Wertesystem an die Hand geben, anhand dessen die Entwicklung ausgerichtet werden soll. Dabei gelten aber nach wie vor die ursprünglichen Clean Code Prinzipien und Praktiken.
Was ist Clean Code?
Clean Code (zu Deutsch: "sauberer Code") ist ein Konzept der Softwareentwicklung, das sich auf die Qualität und Gestaltung des Quellcodes selbst konzentriert. Es geht darum, Code so zu schreiben, dass er nicht nur für den Computer funktioniert, sondern vor allem für menschliche Entwickler leicht zu lesen, zu verstehen, zu warten und zu erweitern ist.
Das Wichtigste im Kürze
- Clean Code ist Code, der leicht zu lesen, zu ändern und zu erweitern ist – und dadurch langfristig günstiger wird.
- Der größte Hebel ist Lesbarkeit, weil Entwickler deutlich mehr Zeit mit Lesen als mit Schreiben verbringen.
- Clean Code Developer baut auf Clean Code auf, erweitert es aber um ein Wertesystem für die tägliche Entwicklungsarbeit.
- Die 4 Werte sind: Wandelbarkeit, Korrektheit, Produktionseffizienz, kontinuierliche Verbesserung.
- Prinzipien wie SRP, DRY, SOLID, SoC senken Kopplung und erhöhen Verständlichkeit.
- Tests (TDD/Unit-Tests) sind nicht „nice to have“, sondern eine Kernbedingung für Korrektheit.
- Refactoring ist kein Extra – es ist der Mechanismus, um Qualität dauerhaft zu halten.
- Tools wie statische Codeanalyse, Formatter/Linter und CI machen Clean Code im Team konsistent umsetzbar.
Projekt besprechen (30 Min)
Sie planen ein konkretes Softwareprojekt, möchten ein bestehendes System weiterentwickeln oder ablösen.
Clean Code Developer: Die 4 fundamentalen Werte
Der Ansatz von Clean Code Developer legt diese 4 fundamentalen Werte zugrunde, an die sich die moderne Softwareentwicklung anlehnen soll. Dabei steht immer im Vordergrund, sich von Beginn an eines Projektes nach diesen Grundlagen auszurichten und das gesamte Projekt über einzuhalten:
Wandelbarkeit
„Design is a process“ – Die Entwicklung und das Design von Software ist ein agiler Prozess. Es gibt keinen definierten Endpunkt, wann eine Software fertig ist. Genauso wenig wie es aus technischer Sicht keine Softwarewartung gibt, bei der proaktiv zu bestimmten Zeitpunkten bestimmte Tätigkeiten ausgeführt werden, wie z.B. der Wartung eines Fahrzeuges. Bei Software hingegen werden Anforderungen und Änderungen flexibel im Laufe des Projektes definiert und umgesetzt.
Damit jederzeit Anpassungen möglich sind, muss die Software eine „saubere“ innere Struktur haben. Damit wird es möglich ein Softwareprojekt über einen längeren Zeitraum kontinuierlich weiterentwickeln zu können, ohne dabei die Kosten in den späteren Projektphasen ansteigen zu lassen. Diese Konstanz von Anpassungen in einer Software, sind ein entscheidendes Kriterium. Vielleicht kennst du Projekte, wo in fortgeschrittenen Projektphasen auch kleine Anpassungen immer schwieriger und aufwendiger zu realisieren waren. Das Kriterium der Wandelbarkeit adressiert diesen Umstand.
Jederzeit in einem Projekt sollen Features zu gleichen Kosten ergänzt werden können. D.h. idealerwiese egal zu welchem Zeitpunkt im Projekt es umgesetzt wird, ist immer mit den gleichen Kosten zu rechnen. Je deutlicher dieser Zusammenhang in einem Projekt ausgeprägt ist, desto höhere ist die Wandelbarkeit.
In der Praxis zeigt sich häufig, dass bei Missachtung des Single Responsibility Principle die Wandelbarkeit darunter leidet. Dieses Prinzip sagt aus, dass eine Klasse oder Methode genau eine Verantwortlichkeit haben sollen, also genau eine Sache machen sollen. Wenn Klassen oder Methoden mehrere Dinge machen, wird es immer schwieriger den notwendigen Überblick für Änderungen zu haben, oder anders ausgedrückt, die Kopplung wird hoch. Zu viele Abhängigkeiten und Side Effects entstehen, wenn die Kopplung hoch ist und dieser Zustand kann später nur sehr schwer wieder korrigiert werden.
Korrektheit
Die Korrektheit definiert, dass eine Software die gestellten funktionalen Anforderungen erfüllen soll, und die Funktionen fehlerfrei die erwartenden Ergebnisse liefern. Doch auch die nicht-funktionalen Anforderungen, wie Ressourcenschonung von Speicher und Prozessorzeit und Antwortzeiten müssen im gestellten Rahmen liegen. Wenn sie alle Anforderungen erfüllt, ist eine Software korrekt.
Für die Korrektheit von Software muss bereits bei der Entwicklung gesorgt werden. Es reicht nicht aus anzunehmen, dass ein nachgelagerter Testprozess die Fehler in der Software findet. Clean Code sagt hier eindeutig, bereits während der Entwicklung Tests durchzuführen, und zwar nach der TDD Methodik (Test Driven Development). Mit TDD wird im Entwicklungsprozess immer mit einem failing Unit-Test gestartet und anschließend der passende Production Code entwickelt. Dieser Prozess wird so lange iterativ durchlaufen, bis alle funktionalen Anforderungen an einen Source Code erfüllt sind.
Damit entfällt das „lästige“ Entwickeln von Unit-Tests im Anschluss an die Programmierung, die oft ohnehin nur „Happy Path“ Tests sind. Wird TDD konsequent ein- und umgesetzt, verbringst du als Programmierer deutlich weniger Zeit im Debugger und kannst dich auf die eigentliche Entwicklungsarbeit konzentrieren. Und als Nebeneffekt ist mit dem Production Code auch der Unit-Test fertiggestellt.
Die Korrektheit kann weiter erhöht werden, wenn Pair Reviews durchgeführt werden und vor der Umsetzung eine Anforderungsanalyse und Konzeptentwicklung stattfinden.
Produktionseffizienz
Jeder Arbeitsschritt, der mehr als einmal durchgeführt wird, sollte automatisiert werden. Die Produktionseffizienz eines Teams hängt direkt mit der Anzahl der automatisierten Tasks zusammen. Gleichzeitig reduziert eine Automatisierung die Fehleranfälligkeit.
Eine hohe Produktionseffizienz bedeutet, dass eine Software über längere Zeit weiterentwickelt werden kann.
Kontinuierliche Verbesserung
Dieser Punkt setzt eine Reflexion über den Prozess selbst als auch auf Ebene der Softwaretechnik voraus. Nur wenn die aktuellen Vorgänge durchleuchtet werden, kann entschieden werden, was anders gemacht und verbessert werden soll. Im Sinne von SCRUM ist diese Vorgehensweise für den Prozess schon fix in den Ablauf integriert, mit der Sprint Retrospektive und dem Sprint Review.
Im Sinne von Clean Code kann die Verbesserung auf Ebene des Source Codes mit Reviews und Refactoring erreicht werden. Refactoring ist ein entscheidendes Element bei Clean Code Development. Wenn eine Source Code nach der Umsetzung ein Clean Code Prinzip verletzt, steht jeweils als Folgeschritt das Refactoring am Plan. Dabei wird auch der Test Code genauso wichtig gesehen, wie der Production Code und es gelten für ihn die gleichen Prinzipien. Beim Refactoring wird entwickelter bereits funktionierender Code nochmals intensiv auf Clean Code Richtlinien hin überprüft. Sind Richtlinien nicht eingehalten oder ergeben sich Verbesserungen, werden diese in den Source Code eingearbeitet. Kontinuierliche Verbesserung ist bei Clean Code schon während der Entwicklung ständig aktiv.
Clean Code Prinzipien: wie programmierst du Clean Code?
Clean Code sagt aus, dass der Coder „sauber“ sein soll, gemeint ist damit, dass er human readable sein soll. Wenn du dir den Vorgang des Programmierens genauer überlegt, kommt man zum Ergebnis, dass Programmieren aus 2 Tätigkeiten mit sehr unterschiedlichen Anteilen besteht. Da wäre das Lesen von bestehenden oder gerade programmierten Source Code und das eigentliche Schreiben von neuem Source Code.
| Akronym | Prinzip (Deutsch) | Relevanz für Clean Code |
|---|---|---|
| S |
Single
Responsibility Principle (SRP) |
Eine Klasse/Methode sollte nur eine einzige Aufgabe haben. |
| O |
Open Closed
Principle (OCP) |
Softwarekomponenten sollen für Erweiterungen offen, aber für Änderungen geschlossen sein. |
| L |
Liskov Substitution
Principle (LSP) |
Subklassen müssen austauschbar sein mit ihren Basisklassen, ohne die Korrektheit des Programms zu beeinträchtigen. |
| I |
Interface
Segregation Principle (ISP) |
Clients sollten nicht gezwungen werden, Interfaces zu implementieren, die sie nicht nutzen (kleinere, spezifische Interfaces). |
| D |
Dependency
Inversion Principle (DIP) |
High-Level-Module sollten nicht von Low-Level-Modulen abhängen. Beide sollen von Abstraktionen abhängen. |
Durch die konsequente Anwendung von SOLID im Design Ihrer Software stellen Sie sicher, dass Ihr Code lose gekoppelt und hoch kohärent bleibt. Dies ist die notwendige Voraussetzung, um die fundamentalen Werte der Wandelbarkeit und Korrektheit zu erfüllen.
Beim Programmieren wird viel mehr Source gelesen
Das Verhältnis von Lesen zu Schreiben beim Programmieren ist grob etwa 10:1 verteilt. Der Hauptanteil beim Programmieren liegt eigentlich am Lesen von Source Code (ganz egal, ob er gerade geschrieben wurde oder bereits vorhanden war). Durch diese Verteilung wird auch klar, ein leicht lesbarer Source Code reduziert den Programmieraufwand erheblich.
Deswegen legt Clean Code so viel Wert auf Refactoring, da das Lesen von Source mit einem Anteil von etwa 10 in die Programmiertätigkeit einfließt. Wenn ein Source Code nicht den Clean Code Richtlinien entspricht, soll durch nochmaliges intensives Durchdenken der Prinzipien ein unmittelbares Refactoring erfolgen. Mit diesem kleinen Zeitaufwand beim Schreiben, kann in Folge durch das Verhältnis 10:1, beim Lesen ein enormer Aufwand eingespart werden.
CISQ schätzt die Kosten schlechter Softwarequalität in den USA (Report 2022) auf mindestens 2,41 Billionen USD; die akkumulierte Technical Debt wird auf ca. 1,52 Billionen USD beziffert.
Welche Prinzipien gibt es bei Clean Code ganz konkret? Wir haben dir hier die wichtigsten Aussagen zusammengefasst:
Boy Scout Rule
Diese Regel ist abgeleitet von Pfadfindern und besagt, dass du einen Source Code immer besser verlassen solltest, als du ihn vorgefunden hast. Wenn dir also Verbesserungen im Sinne der Clean Code Vorgaben an Source Code auffallen, dann setze sie um.
DRY – Don’t Repeat Yourself
Wiederhole dich nicht – es darf kein Teil im Source Code doppelt vorhanden sein. In den meisten Fällen betrifft diese Regel redundante Stellen im Source Code, die mehrfach eingesetzt werden und in eine Methode verschoben werden könnten.
Eine Logik darf nur an exakt einer Stelle definiert sein. Wenn die gleiche oder eine ähnliche Logik an mehreren Stellen vorhanden ist, erzeugt das mehr Lesearbeit und verwirrt zudem.
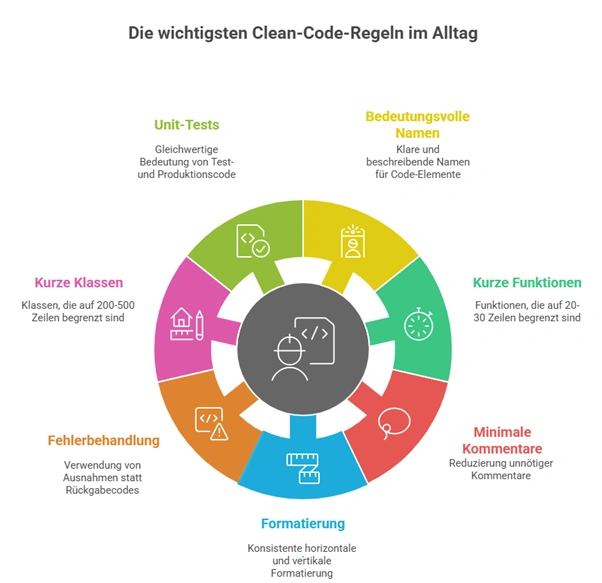
Meaningful Names für Klassen, Methoden, Variablen…
Neben den Keywords einer Programmiersprache machen Namen den größten Teil an Source Code aus. Mit einer guten Namensgebung kann das Lesen vereinfacht und das Verständnis von Source Code deutlich gesteigert werden. Als Programmierer verwenden wir Namen für verschiedenste Elemente beim Entwickeln von Software:
- Variablen
- Funktionen
- Klassen
- Parameter
- Packages / Namespaces
- Files
- Verzeichnisse
- ...
Namen sollen so gewählt sein, dass sie möglichst klar beim Lesen identifizieren, was damit bezeichnet wird. Ein Kommentar zum Verständnis eines Variablennamens solle nicht notwendig sein.
Funktionen
Funktionen sollen kurz sein, als Grundregel gilt etwa 20 bis max. 30 Zeilen. Mehr Code sollte eine Funktion nicht umfassen. Alles was diesen Wert übersteigt, lässt sich nur sehr schwer auf einmal im Kopf behalten, um z.B. eine Anpassung zu machen. Zudem lassen sich kurze Funktionen einfacher mit Unit-Tests abdecken.
Die Anzahl an Parameter sollte auf max. 3 reduziert werden, sogar besser nur 1 oder 2 Parameter. Falls Funktionen mehr Parameter benötigen sollten, ist es besser ein Objekt als Parameter zu übergeben.
Kommentare
Sollen auf ein Minimum reduziert werden. Nichts ist so schädlich wie ein „lügendes“ Kommentar. Clean Code ist mit Kommentaren eindeutig, sie sind schlichtweg an vielen Stellen nicht notwendig und erhöhen nur den Aufwand beim Programmieren. Neben dem Source Code müssen auch Kommentare angepasst werden, was zwangsweise bei Anpassungen zu Situationen führt, wo zwar der Source aber nicht das Kommentar angepasst wird. Was zur Folge hat, dass der Kommentar „lügt“.
Immer wenn du dich in der Situation wiederfindest, einen Kommentar schreiben zu wollen, solltest du nochmals intensiv über den Source Code nachdenken und diesen anpassen. In den meisten Fällen wird der Kommentar dann überflüssig.
Formatierung
Clean Code unterscheidet zwischen Richtlinien für die horizontale und vertikale Formatierung. Auch wenn hier die IDEs in der Zwischenzeit viel Aufwand ersparen, die grundsätzliche Formatierung von Source Code liegt beim Programmierer.
So beschreibt Clean Code vertikale als auch horizontale Openness between Concepts, was die Abstände an zusammengehörenden bzw. nicht zusammengehörenden Elementen beschreibt. Andere Begriffe aus der Formatierung sind Vertical Density und Distance sowie Horizontal Alignment und Indentation.
Error Handling
Clean Code hat für das Behandeln von Fehlern sehr klare Vorgaben. Die beiden wichtigsten daraus sind: verwende Exceptions statt Return Codes und gib kein null an eine Funktion oder von dort zurück.
Wenn in einer Funktion ein Fehler passiert, dann wirf diesen Fehler an den Aufrufer zurück. Das Zurückgeben von speziellen Return Codes ist hier keine saubere Lösung, weil es nicht zu einer besseren Codestruktur beiträgt. Solche speziellen Rückgabewerte müssen im Aufrufer ebenfalls extra behandelt werden und umgehen nur das Exception Handling, welches ohnehin in modernen Programmiersprachen vorhanden ist.
Ähnlich ist es mit der Übergabe oder Rückgabe von null Werten an und von Funktionen. Wenn null Werte übergeben werden, müsste am Beginn jeder Funktion ein null-Check erfolgen. Diese Checks machen den Source Code länger und schwieriger zu verstehen. Clean Code sagt hier eindeutig, dass keine nulls übergeben werden dürfen. Bei Programmiersprachen wie z.B. Kotlin ist diese Erkenntnis schon eingearbeitet. Variablen, die null-Werte enthalten dürfen, müssen hier entsprechend markiert werden.
Klassen
Ebenfalls wie Funktionen, sollen Klassen auch kurz sein. Als Grundregel gilt hier 200 bis max. 500 Zeilen, wobei je kürzer desto besser.
Eine Klasse soll zudem das Single Responsibility Principle erfüllen, also exakt eine Aufgabe haben und diese möglichst präzise und fehlerfrei erfüllen. Wenn dieses Prinzip eingehalten wird, ergibt sich automatisch eine Klasse mit weniger Zeilen und einer höheren Kohäsion (die Kohäsion soll möglichst hoch sein und sagt etwas über den logischen Zusammenhang des Codes aus). Und das Ganze noch bei einer möglichst losen Kopplung (also möglichst wenig Abhängigkeiten zwischen Klassen).
Unit Tests und TDD
Beide spielen bei Clean Code eine wichtige Rolle. Clean Code stuft die Wichtigkeit von Test Code gleich hoch ein wie den eigentlichen Production Code. Damit gelten für Test Code die gleichen Ansätze und er soll auch nach den gleichen Grundsätzen entwickelt sowie refactored werden.
Clean Code adressiert allerdings die oft nachlässige Einstellung zu Unit Tests, indem als Paradigma die Entwicklung mittels TDD also Test Driven Development festgelegt wird. Der Vorgang könnte als eine Art agiles Unit Testing gesehen werden.
Bei TDD wird in iterativen Schritten immer zuerst der Unittest nur so weit entwickelt, dass er fehlschlägt. Im Anschluss wird immer ein Teil des Production Code entwickelt, bis der Unit Test durchläuft. Die Entwicklung von Unit Test und Production Code erfolgt dabei abwechselnd und zu kleinen Teilen. Dieser Vorgang wird so lange wiederholt, bis der Production Code die gestellten Anforderungen abdeckt.
Bei der TDD Vorgehensweise verbringt der Programmierer weniger Zeit im Debugger, weil der Unit Test die Testwerte ohnehin automatisch auswertet. Weiterer Vorteil: am Ende der Entwicklung ist Production Code und Unit Test vorhanden.
Clean Code Praktiken: Welche Design Patterns sind wichtig?
Nachdem uns Clean Code eine Reihe von Prinzipien an die Hand gibt, welche sich mit dem Source Code selbst befassen, legt es auch fest, mit welchen Design Patterns die Struktur einer Software aufgebaut werden soll.
Open Closed Principle OCP
Softwarekomponenten (Klassen, Module, Funktionen, …) sollen offen für Erweiterungen sein, aber geschlossen für Änderungen. Gemeint ist damit eine vorausschauende Programmierweise, um zukünftige Anpassungen schon voraus anzunehmen. Anpassungen sollen immer in neuen Klassen erfolgen, existierender Code soll unangetastet bleiben.
Erreicht wird es, indem immer Richtung Interfaces programmiert wird, mit denen eine lose Kopplung möglich wird. Erweiterungen werden in neue Klassen eingefügt, die vom gleichen Interface abgeleitet sind.
Information Hiding Principle IHP
Dem Verbergen von Informationen liegt aus den Programmiersprachen die Datenkapselung zugrunde, welche das IHP ermöglichen. Es soll immer die niedrigste mögliche Sichtbarkeit für Variablen und Methoden eingesetzt werden. Ein generelles Verwenden des Access Modifiers public für alle Properties oder Methoden soll vermieden werden. Wenn möglich sollen getters und setters überhaupt weggelassen werden, wenn sie nicht gebraucht werden.
Damit wird erreicht, dass Programmteile großen Abhängigkeiten aufweisen und leichter angepasst werden können. Interne Mechanismen können einfacher verändert werden, wenn nur die notwendigen Informationen offengelegt werden.
Projekt besprechen (30 Min)
Sie planen ein konkretes Softwareprojekt, möchten ein bestehendes System weiterentwickeln oder ablösen.
Favour Composition over Inheritance FCOI
Eine Komposition ist gegenüber Vererbung zu bevorzugen, da hier weniger interne Details „mitgeschleppt“ werden müssen und die Kopplung reduziert wird. Vererbung könnte als „white box reuse“ und Komposition als „black box reuse“ bezeichnet werden.
Wenn Vererbungshierarchienumfassender werden, müssen mit jeder neu hinzukommenden Klasse bestimmte Methoden überschrieben werden, um die Funktion zu gewährleisten. Besser ist es, das Verhalten von Klassen in eigene Funktionsklassen auszulagern und diese in anderen Klassen einzusetzen..
Damit werden Vererbungshierarchien aufgebrochen, das Single Responsibility Principle eingehalten und der Umfang von Klassen reduziert.
Separation of Concerns SOC
Stellt sicher, dass ein Programm modular aufgebaut ist. Es wird erreicht, indem die Einzelteile voneinander gekapselt werden und über eine definierte Schnittstelle angesprochen werden können.
Der Source Code soll in Klassen geteilt werden, die Schnittstelle soll jeweils über ein Interface definiert sein, und zusammengehörende Klassen sollen in einem Package / Namespace zusammengefasst sein.
Single Responsibility Principle SRP
Dieses Prinzip wurde im Text schon an mehreren Stellen angesprochen, da es bei Clean Code eine zentrale Rolle spielt. Aussage ist, jedes Element in einem Source Code soll genau eine Funktion haben und diese perfekt erfüllen.
Die Einhaltung dieses Prinzips erhöht die Verständlichkeit des Source Codes und hält die Kopplung niedrig.
Dependency Inversion Principle DIP
Oder Abhängigkeiten-Umkehrungs-Prinzip. Es sagt aus, dass high-level Module keine Abhängigkeiten zu low-level Modulen besitzen sollen. Änderungen in einer unteren Ebene dürfen keine Auswirkungen auf höhere Ebenen haben.
Da die Funktionen der unteren Ebenen auf höheren Ebenen eingesetzt werden, kann dies nur erreicht werden, wenn die untere Ebene Interfaces bereitstellt. Die höheren Ebenen verwenden dann nur die Interfaces und nicht konkrete Klassen. Wie die Funktionen auf den unteren Ebenen im Detail umgesetzt sind, ist damit verborgen.
Integration Operation Segregation Principle IOSP
Jede Funktion soll entweder andere Funktionen aufrufen (Integration) oder soll Logik (Operation) enthalten. Mit Logik oder Operationen sind alle Funktionen gemeint, die tatsächliche Business Logic enthalten. Die Business Logic soll genau eine gestellte Anforderung lösen, darin sollen dann z.B. keine API oder IO Aufruf erfolgen. Diese Aufrufe wären dann Integration.
Integration und Operation soll klar getrennt sein. Erstellte Business Logic soll dann in eigenen Integration Funktionen oder Integration Klassen mit anderer Business Logic verknüpft (integriert) werden.
Tipps für den Praxiseinsatz
Wann es ist, nun für dich wichtig, sich mit Clean Code zu beschäftigen?
Je nach deinem aktuellen Job hängt es davon ab, wie tief du in welche Bereiche einsteigen solltest. Wenn du als Programmierer vor der Aufgabe stehst, ein umfangreicheres Projekt zu entwickeln, solltest du dich zuerst mit den Prinzipien vertraut machen. Damit kannst du beim Schreiben von Source Code gleich die wichtigsten Clean Code Vorschläge einhalten und dein Source Code ist von Beginn an „sauber“. Bevor du mit der Umsetzung konkreter Anforderungen beginnst und die Softwarearchitektur dafür festlegst, macht es Sinn sich intensiver mit den Praktiken und Design Patterns vertraut machen.
Auch wenn du z.B. Projektleiter auf der Auftraggeberseite bist, ist es durchaus von Vorteil, wenn du dich mit Clean Code vertraut machst. Aus Sicht einer nachhaltigen und langfristen Entwicklung einer Software, spielen hier vor allen die unter Praktiken beschriebenen Punkte eine wesentliche Rolle. Wird die Software in ihrer Struktur nicht von Beginn an nach Clean Code Vorschlägen gestaltet, kann es passieren, dass im Projektfortschritt Erweiterungen nur mit höherem Aufwand oder fast gar nicht mehr umsetzbar sind.
So und jetzt kann es losgehen
Lade einfach unser 160 Seiten umfassendes Whitepaper mit mehr Details und konkreten Beispielen herunter und lege los. Du kannst mit Clean Code in Deinem bestehenden Projekt beginnen oder du kannst bei deinem nächsten neuen Projekt losstarten.
Brauchst du mehr Infos, schreibe mir.
FAQ
Welche Vorteile bietet die Einhaltung von Clean Code Prinzipien für ein Softwareprojekt?
Die Einhaltung von Clean Code Prinzipien bietet einen entscheidenden Wettbewerbsvorteil, da sie die Wartungskosten senkt und die Entwicklungsgeschwindigkeit langfristig hochhält. Der Hauptvorteil liegt in der drastischen Reduzierung der Technischen Schuld: Gut strukturierter, lesbarer Code minimiert das Risiko, dass kleine Änderungen in einem Bereich zu unvorhergesehenen Fehlern in einem anderen Bereich führen. Dies führt zu weniger Debugging-Zeit und ermöglicht es dem Entwicklungsteam, sich auf die Implementierung neuer Features statt auf das Beheben alter Probleme zu konzentrieren. Darüber hinaus steigert er die Zusammenarbeit und die Einarbeitungszeit neuer Teammitglieder, da die Softwarearchitektur und -logik leichter verständlich sind.
Wie kann ich Clean Code in meinem bestehenden Projekt anwenden (Boy Scout Rule)?
Die Anwendung von Clean Code in einem bestehenden, möglicherweise unsauberen Projekt beginnt nicht mit einer zeitraubenden, kompletten Überarbeitung. Die wichtigste und praktikabelste Methode ist die Boy Scout Rule: Verlasse den Code immer in einem besseren Zustand, als du ihn vorgefunden hast. Bei jeder Interaktion – sei es zur Fehlerbehebung oder zur Implementierung einer kleinen Funktion – nimmst du dir kurz Zeit für ein kleines Refactoring im unmittelbaren Umfeld deiner Änderung.
Das kann das Umbenennen einer unverständlichen Variable, das Aufteilen einer zu langen Methode oder das Entfernen doppelten Codes sein. Dieser kontinuierliche, inkrementelle Prozess verhindert, dass die Technische Schuld weiterwächst, und führt über die Zeit zu einer stetigen, spürbaren Verbesserung der Codebasis.
Welche Tools helfen wirklich (Linter, SonarQube, Formatter) – und welche sind „nice to have“?
Ein Formatter ist fast immer „Must-have“, weil er Diskussionen über Stil beendet und den Code im Team konsistent macht, idealerweise automatisch bei jedem Commit. Ein Linter ist ebenfalls sehr wertvoll, weil er typische Fehler und schlechte Patterns früh abfängt und Standards erzwingt, bevor sie in Reviews Zeit kosten. SonarQube (oder ähnliche Plattformen) ist besonders dann stark, wenn mehrere Teams/Repos im Spiel sind oder du Qualitätsmetriken sichtbar machen willst; für kleine Projekte kann es „nice to have“ sein, wird aber schnell „wirklich hilfreich“, sobald technische Schulden wachsen. Insgesamt gilt: Tools sind am wirksamsten, wenn sie nicht optional sind, sondern in CI/Pre-Commit integriert werden – sonst bleibt Clean Code eine gute Absicht statt gelebter Praxis.
Gleich mehr Infos erhalten ✍️
Das könnte Sie auch interessieren:
- Embedded Systems Programmierung und Softwareentwicklung - was ist das?
- Digitalisierung in Krankenhäusern: effiziente Lösungen für den Gesundheitssektor
- Wie Unternehmen Digitalisieren
- Kosten und CO2 reduzieren mit smarten Software-Lösungen
- Hohe Energiepreise? So hilft Energiemanagement-Software der Industrie

")